Reader fields (again)

Reader Fields and how to handle them to balance security and performance is a never ending topic. Let us have a a closer look what actually happens. Let us assume we have a view with 500,000 document, where a particular user has access to 77 documents (which is not so uncommon in big organizations). In the first case the view is sorted by some criteria (case number, date or whatever) that scatters the 70 documents all over the database.
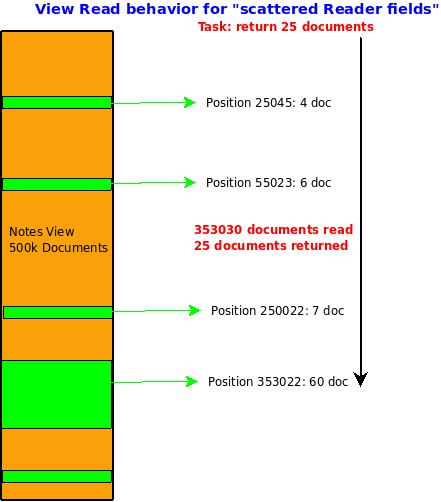
When the user e.g. opens that view from the web requesting the default 25 entries, the Domino server actually will more than 350,000 documents. It needs to instantiate a document object and evaluate access control rules for it. These are costly (read time and memory) operations. Performance will not meet any user expectation. Ironically this is hardly discovered by developers since they test with a few hundred documents and very often have universal access. With a little change of the view layout, the situation changes completely. We take the same view but categorize it by e.g. by @Unique(DocAuthors:DocReaders) which would list all documents for a specific reader (remember: an Author field includes Read Access Rights).
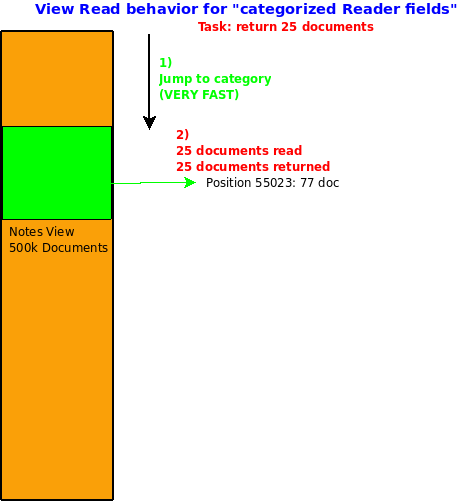
Now the Domino Server does an index search which is very fast going after a build index and reads exactly 25 documents. So with a little change in the view layout we removed 99.9929% of the document reads (bad news for hardware sellers). Looks good.... but you will say: wait a second. One user can have read access because her name is in a Reader/Author field, she might be member of a group or have a specific role, the single category only will show me one of that entries at a time.And you are right. To cover that a little more work is needed. There are two approaches to handle this problem. The first is from a functional angle, the second one involved code. The functional angle: The various reasons why a users can read a document typically translate into a business functionality. First there are "My Documents". That would be all the documents where a user is explicitly named for being the requestor, approver, reviewer etc., Then there are e.g. Revision Documents where the users has the role [Revisor] or Audit Document where the user has the role [Audit]. And then there are the documents that belong to my department, which translates into a group name. To reflect that in an UI you need to populate a dropdown box with the human values in the UI and the technical value in als result. And voila single category access will work. A UI could look like this:
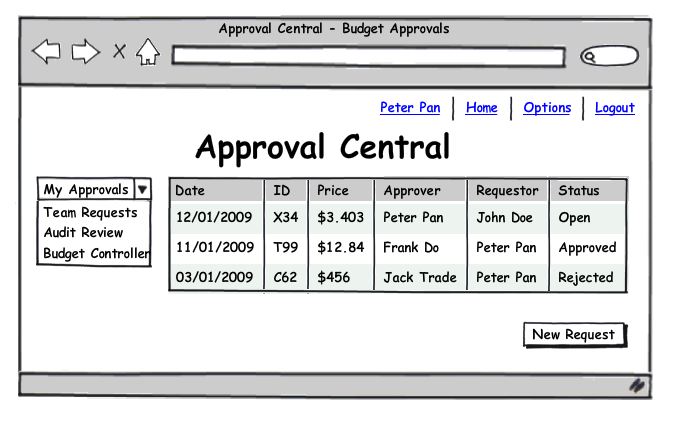
(UI created with Balsamic Mockups). I have tested this variation over-and-over by giving users both options and monitoring what they choose: access by business role as described here or (see below) flat anything. Business users pick the business role access in a high 90% range of cases for their daily work.
The code version: Create a $$ViewTemplate for your view. Do not add a $$ViewBody field (or the embedded view element). Add a RichText field "Body" and a webQueryOpen agent. That wqo agent writes into that body field which effectively becomes our view display. For creative minds: you are not limited by a table display. The agent looks up all Roles/Groups/Names of the current user by leveraging @UserNameList and makes one call to getViewEntriesByKey. The trick here: a) use ViewEntries not Documents b) have the UNID in one column and use a LotusScript list not to output a document twice c) use a sorting Dojo Table to get the stuff sorted (optional). The nice side effect of the agent: you can output as many lines as you deem fit.
Some sample code:
This LotusScript was converted to HTML using the ls2html routine,
provided by Julian Robichaux at nsftools.com.
To make that all work you need a few fields on your $$Viewtemplate.. form:
(Note: in this sample there is no processing of the UNIDs). YMMV
Update: Some more links to the topic on developer works:
When the user e.g. opens that view from the web requesting the default 25 entries, the Domino server actually will more than 350,000 documents. It needs to instantiate a document object and evaluate access control rules for it. These are costly (read time and memory) operations. Performance will not meet any user expectation. Ironically this is hardly discovered by developers since they test with a few hundred documents and very often have universal access. With a little change of the view layout, the situation changes completely. We take the same view but categorize it by e.g. by @Unique(DocAuthors:DocReaders) which would list all documents for a specific reader (remember: an Author field includes Read Access Rights).
Now the Domino Server does an index search which is very fast going after a build index and reads exactly 25 documents. So with a little change in the view layout we removed 99.9929% of the document reads (bad news for hardware sellers). Looks good.... but you will say: wait a second. One user can have read access because her name is in a Reader/Author field, she might be member of a group or have a specific role, the single category only will show me one of that entries at a time.And you are right. To cover that a little more work is needed. There are two approaches to handle this problem. The first is from a functional angle, the second one involved code. The functional angle: The various reasons why a users can read a document typically translate into a business functionality. First there are "My Documents". That would be all the documents where a user is explicitly named for being the requestor, approver, reviewer etc., Then there are e.g. Revision Documents where the users has the role [Revisor] or Audit Document where the user has the role [Audit]. And then there are the documents that belong to my department, which translates into a group name. To reflect that in an UI you need to populate a dropdown box with the human values in the UI and the technical value in als result. And voila single category access will work. A UI could look like this:
(UI created with Balsamic Mockups). I have tested this variation over-and-over by giving users both options and monitoring what they choose: access by business role as described here or (see below) flat anything. Business users pick the business role access in a high 90% range of cases for their daily work.
The code version: Create a $$ViewTemplate for your view. Do not add a $$ViewBody field (or the embedded view element). Add a RichText field "Body" and a webQueryOpen agent. That wqo agent writes into that body field which effectively becomes our view display. For creative minds: you are not limited by a table display. The agent looks up all Roles/Groups/Names of the current user by leveraging @UserNameList and makes one call to getViewEntriesByKey. The trick here: a) use ViewEntries not Documents b) have the UNID in one column and use a LotusScript list not to output a document twice c) use a sorting Dojo Table to get the stuff sorted (optional). The nice side effect of the agent: you can output as many lines as you deem fit.
Some sample code:
Sub Initialize Dim s As New NotesSession Dim doc As NotesDocument Dim db As NotesDatabase Set doc = s .DocumentContext Set db = s .CurrentDatabase Dim rt As NotesRichTextItem Set rt = New NotesRichTextItem (doc , "Body" ) Call test1 (doc , rt ) 'Just one test Dim v As NotesView Dim catList As Variant Set v = db .GetView ( "catByAccess" ) catList = doc .GetItemValue ( "UserNameList" ) Call RenderViewToRT (v , rt , catList ) End SubSub RenderViewToRT (v As NotesView , rt As NotesRichTextItem , catList As Variant ) 'catlist is an array with the list of categories to lookup Dim i As Integer Dim k As Integer Dim m As Integer Dim vec As NotesViewEntryCollection Dim ve As NotesViewEntry Dim colVals As Variant Dim curVal As Variant On Error Goto Err_RenderViewToRT Call rt .AppendText ( |<table class="data">| ) Call rt .AddNewline (1 ) 'One lookup at a time For i = 0 To Ubound (catList ) Step 1 Set vec = v .GetAllEntriesByKey (catList (i ) ) If vec .Count > 0 Then Call rt .AppendText ( |<tr class="success"><td colspan="7">| + Cstr (vec .Count ) + | entries found for | +catList (i ) + |</td></tr>| ) Set ve = vec .GetFirstEntry Do Until ve Is Nothing Call rt .AppendText ( |<tr>| ) For k = 0 To Ubound (ve .ColumnValues ) Step 1 colVals = ve .ColumnValues (k ) Call rt .AppendText ( "<td>" ) If Isarray (colVals ) Then For m = 0 To Ubound (colVals ) Call rt .AppendText (colVals (m ) ) Call rt .AppendText ( "<br />" ) Next Else Call rt .AppendText (colVals ) End If Call rt .AppendText ( "</td>" ) Next Call rt .AppendText ( |</tr>| ) Set ve = vec .GetNextEntry (ve ) Loop Else 'This is for demo only --- in production this info is useless Call rt .AppendText ( |<tr class="failure"><td colspan="7">No data found for | +catList (i ) + |</td></tr>| ) End If Next Call rt .AppendText ( "</table>" ) Call rt .AddNewline (1 ) Exit_RenderViewToRT : Exit Sub Err_RenderViewToRT : Print Error$ & " in line " & Cstr ( Erl ) Call rt .AppendText ( Error$ & " in line " & Cstr ( Erl ) ) Call rt .AddNewline (1 ) Resume Exit_RenderViewToRT End Sub
provided by Julian Robichaux at nsftools.com.
- QUERY_STRING:Text, Single Value, Editable: to capture the Query String
- UserNameList:Names, MultiValue, computed:
tmpUsedHere := @DbColumn("Notes":"Cache";"";"LookforGroupsAndRoles";1); tmpThisUser := @Trim(@Replace(@UserNamesList;"*";"")); @Keywords(tmpUsedHere;tmpThisUser) - :
(Note: in this sample there is no processing of the UNIDs). YMMV
Update: Some more links to the topic on developer works:
- Using and understanding Reader Names fields in IBM Lotus Notes and Domino
- Lotus Notes/Domino 7 application performance: Part 2: Optimizing database views
- List of all performance related articles
Posted by Stephan H Wissel on 28 February 2009 | Comments (6) | categories: Show-N-Tell Thursday
