Designing data sources - square pegs into round holes

Stephen Mitchel translated the end of verse 21 of the Dao De Ching ( 何以知衆甫之狀哉?以此。= wu he yi zhi zhong fu zhi zhuang zai? yi ci.) as " How do I know this is true? I look inside myself and see.". Lao zhu could have been a software platform or framework architect  . Getting the gist of a platform often requires a zen like approach. Unfortunately in the heat of delivery pressures things get lost and we end up with "Frankenworks" instead of "Frameworks", where functionality works, but feels rather "bolted on".
. Getting the gist of a platform often requires a zen like approach. Unfortunately in the heat of delivery pressures things get lost and we end up with "Frankenworks" instead of "Frameworks", where functionality works, but feels rather "bolted on".
Currently there is work underway to make XPages a first class RDBMS front-end. The data source looks very promising, nevertheless prompted me to reflect on the nature of data access, like I mused about structures before. There are some structural differences between a document centric approach (Domino, XMLDB, XForms, ObjectDB, JsonDB etc) and a relational database. Doing justice to both sides poses a formidable challenge:
So what does that mean for the design of additional data sources in Domino? There are two possible approaches which luckily can co-exist since they are not mutually exclusive: follow the nature of Domino or follow the nature of the source (not the nature of the force, that's for others). The current OpenNTF extlib approach is the later: it is designed around the relational feature set.
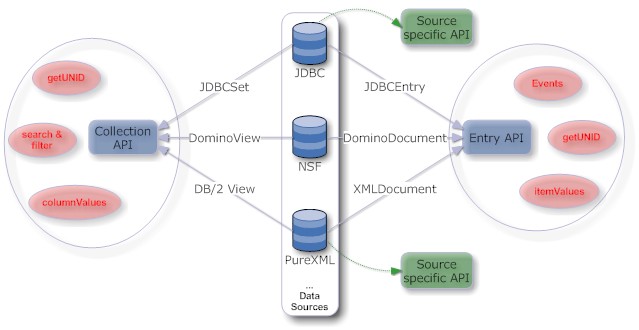
Going forward I would like to see data sources that build on the duality of the Domino data access: the read-only collection and the read/write document.
. Getting the gist of a platform often requires a zen like approach. Unfortunately in the heat of delivery pressures things get lost and we end up with "Frankenworks" instead of "Frameworks", where functionality works, but feels rather "bolted on".
Currently there is work underway to make XPages a first class RDBMS front-end. The data source looks very promising, nevertheless prompted me to reflect on the nature of data access, like I mused about structures before. There are some structural differences between a document centric approach (Domino, XMLDB, XForms, ObjectDB, JsonDB etc) and a relational database. Doing justice to both sides poses a formidable challenge:
- The nature of a relational database is a flat set. A set of rows and columns that get created, read, updated and deleted. It is always about a set, that more than often can yield from more than one table. There is no such thing as a single record, it is just a set with one member. All OR-Mappers struggle with this
- The nature of Domino the the document. Data is stored in documents. Collections (views/folders/search/all) are designed to get access to a document (set). The result of this nature is a dual access to data: there is the collection which is read only (and can be flat or hierarchical) and there is the document which is read/write where data changes happen.
- The document has a predefined set of meta data absent from a relational table: ID, access control, various dates, hierarchy (isResponse) etc. One could add those to an individual database schema, but they can't be taken for granted in RDBMS (a story for another time: designing a RDBMS schema to work well with XPages)
- The document sports structured data. In Domino that are multi-value fields, in other NoSQL databases these structures can be more complex. In RDBMS these structures are splattered across multiple tables and pulled back together with JOIN statements. This makes it easy to run reports or do mass-updates, but makes transporting a logical entity from one database to another a pain
- The dominating clause in RDBMS is
WHEREwhich is needed for all operations including updates, while Domino acts on the current document (doc.save) - The document is closely connected to the Notes/Domino event model. Both XPages and the classic Notes client (and to a lesser extend classic Domino) offer rich data events:
queryNewDocument, queryOpenDocument, postOpenDocument, querySaveDocument, postSaveDocumentetc. - SQL doesn't provide an event model, but the various RDBMS implementation provide triggers that serve a similar purpose that run stored procedures (and are mostly written in incompatible flavors of SQL - check SwissQL for translating them). I'm sure about INSERT, UPDATE and DELETE triggers as equivalent to query/post save events. I haven't looked for a while, but last time I checked SELECT wouldn't trigger a stored procedure, but you could call one directly.
- The splattering of data across tables in RDBMS led naturally to another capability of relational databases, that comes in handy for large manipulations too: transactional integrity. If all you need is saving one document, there is no imminent need for a transaction mechanism, distributing data over multiple (parent, child) tables however mandates an integrity protection
So what does that mean for the design of additional data sources in Domino? There are two possible approaches which luckily can co-exist since they are not mutually exclusive: follow the nature of Domino or follow the nature of the source (not the nature of the force, that's for others). The current OpenNTF extlib approach is the later: it is designed around the relational feature set.
Going forward I would like to see data sources that build on the duality of the Domino data access: the read-only collection and the read/write document.
- Each data source will have 2 elements: a read-only collection and a read/write entry/record/document
- These sources have the same method signatures as DominoDocument and DominoView. So in a design a developer could swap them out for each other.
MyRDBMSSource.getItemValueString("Location")would work the same way asDominoDocument.getItemValueString("Location"). For an RDBMS developer that might look a little strange, but only caries a one time learning affordance, greatly outweighted by the benefit of swappable sources. Of course the parameters would be rather different. In a RDBMS source there probably would be a parameter to define what getDocumentUniqueID would return. - All the document events would fire with every data source
- Data sources can implement additional tags to offer access matching their nature
- enhanced JDBC source following the Domino pattern
- Domino data source encapsulating the inversion of logging pattern
- DB/2 PureXML data source. It would use the standard JDBC approach for the collections and PureXML to read/write document data. It would implement the spirit of NSFDB2 without the constraints of replicating all NSF features (data only)
- Sharepoint. One could build Sharepoint front-ends that survive a Sharepoint upgrade without the need to rewrite them
- IBM MQ
- Web services (take a WSDL and make a form)
- CouchDB
- 3270 Terminal / IBM HATS
- HTML5 storage
Posted by Stephan H Wissel on 13 September 2011 | Comments (1) | categories: XPages