Handle HTTP chunked responses

Objects I need a lot of objects. When dealing with APIs there is one fundamental question to answer: how much data do you want to retrieve?
The old school answer: let's page results, 25 at a time. Then infinite scrolling came along and changed expectations.
I got some chunk for you
One way to operate is for the server to send all data, but using Transfer-Encoding: chunked (RFC 9112) in the header and deliver data in several packages, aptly named chunks. A client can process each chunk on arrival to allow interactivity before data transmission concludes.
However this requires adjustments on both sides. The server needs to send data with a clear delimiter, e.g. \n (newline) and the client needs to process the data as a stream
The usual way won't work
We typically find code like this:
fetch(url)
.then((resp) => resp.json())
.then((json) => {
for (let row in json) {
addRow(json[row], parentElement);
}
});
fetch hides a lot of complexity, we need to handle when we process a chunked result as it arrives.
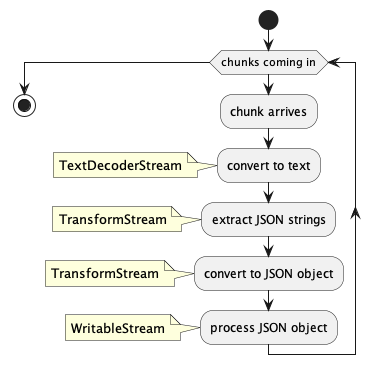
HTTP data arrives as stream of char, not as string. So the first transformation is a conversion to string using a TextDecoderStream
This is followed by a transformation into text snippets, using the TransformStream interface, that can be treated with JSON.parse. The special challenge there is that a chunk might split a line in the middle leaving the first and last line unusable. The solution is not to process the last line, but prepend it to the next chunk and only flush it once the stream ends.
/* Chops arriving chunks along new lines,
takes into account that a chunk might end middle of line */
const splitStream = () => {
const splitOn = '\n';
let buffer = '';
return new TransformStream({
transform(chunk, controller) {
buffer += chunk;
const parts = buffer.split(splitOn);
parts.slice(0, -1).forEach((part) => controller.enqueue(part));
buffer = parts[parts.length - 1];
},
flush(controller) {
if (buffer) controller.enqueue(buffer);
}
});
};
Next step is to convert the text lines into individual JSON objects, again using the TransformStream interface. Note the conditions. They ensure we don't process [ or ].
/* Parses JSON if row looks like JSON (with eventual comma at end of line) */
const parseJSON = () => {
return new TransformStream({
transform(chunk, controller) {
// IGONRES THE [ and ]
if (chunk.endsWith(',')) {
controller.enqueue(JSON.parse(chunk.slice(0, -1)));
} else if (chunk.endsWith('}')) {
controller.enqueue(JSON.parse(part));
}
}
});
};
Finally a WritableStream provides the destination where data gets processed.
The whole thing gets wired up using pipeThrough and pipeTo methods
await httpResponse.body
.pipeThrough(new TextDecoderStream())
.pipeThrough(splitStream())
.pipeThrough(parseJSON())
.pipeTo(jsonToTableRow(insertPoint));
You can try for yourself. Tip: to see the effect fully use the browser's developer tools to simulate a slow connection.
Just to be clear: There's no all-over speed gain to be had. I simulated 5000 entries over 5G, both fetch and chunked took about 9 seconds. However using "classic fetch" users stared for 9 seconds at an empty screen, while in the other case they instantly can interact with the data. Big win in "perceived speed".
As usual YMMV
Posted by Stephan H Wissel on 04 July 2023 | Comments (0) | categories: DRAPI JavaScript WebDevelopment