Myth Buster: NSF doesn't scale

In a lot of customer discussions I hear: "Oh we need to go RDBMS since Notes' NSF doesn't scale". Which is an interesting statement. When digging deeper into that statement, I get a number of reasons why they believe that:
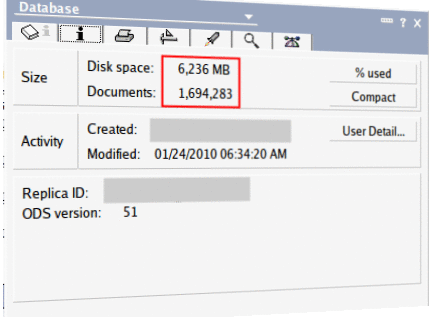
(atually not the graphic, but the live property box using my Notes client). The question quickly arises how the acceptable performance of such a database can be achieved. There are a few pointers to observe:
- Somebody told them
- They had a problem in R4
- The application got slower and slower over the years (and yes it's that same old server
- The workflow application using reader fields is so slow
- They actually don't know
(atually not the graphic, but the live property box using my Notes client). The question quickly arises how the acceptable performance of such a database can be achieved. There are a few pointers to observe:
- Watch your disk fragmentation (troubleshooting tip on the Notes and Domino wiki)
- Be clear about your reader and author fields usage. In case the RDBMS fans insist on their solution, ask them to build the reader field equivalent in RDBMS and measure performance then.
- Watch your view selection formulas carefully. (You don't use @Now, @Today, @Yesterday or @Tomorrow do you?)
- You want to use DAOS to keep attachments out of the NSF (helps with fragmentation) -- don't forget to buy a disk for your transaction log.
Posted by Stephan H Wissel on 23 January 2010 | Comments (6) | categories: Show-N-Tell Thursday