The Network vs. the Tree

When I started to use Lotus Notes in version 2.1 (thanks to these guys) my primary interest wasn't to learn a new technology (I consider learning new technologies as icing on the cake), but to find a suitable tool to manage semi structured information. At that time computers mostly dealt with structured data or individual storage for pre-print artifacts (today known as Office documents). My main interests were and still are Knowledge Management (KM) and eLearning which IMHO are just different stages of the same thing: acquisition, provision and retention of capabilities.
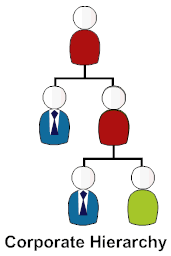 The trickiest problem in KM and to a large extend in eLearning is the classification of items. Taking a hint from classical science the first approach was to use a Taxonomy to build a tree of classification. Classification tree are well established and deeply entrenched in corporate hierarchies: a human is a hominid is a primate is a mammal is a vertebrate is a animal from the realm of living beings. Tom is an engineer who works for Frank who is a team leader who reports to Sue who is a development manager working for Cloe who is head of development reporting to Steve who is CTO reporting to Annabel who is CIO reporting to CEO Jack and the board. Somehow it didn't work. The going joke is: " If you want to get rid of job competitors internally, make sure they sit in the Taxonomy committee, that will tie them up and frustrate them down." Truth is: not everything fits into an hierarchy and agreeing on a term as the single permissible label for an item is a pipe dream (and what you would have to smoke in that pipe would be illegal in most jurisdictions). Especially with the rise of " PC" a committee might come to the compromise to call something " a human muscular traditional digging device" while mentally sane people will insist to " Call a spade a spade".
The trickiest problem in KM and to a large extend in eLearning is the classification of items. Taking a hint from classical science the first approach was to use a Taxonomy to build a tree of classification. Classification tree are well established and deeply entrenched in corporate hierarchies: a human is a hominid is a primate is a mammal is a vertebrate is a animal from the realm of living beings. Tom is an engineer who works for Frank who is a team leader who reports to Sue who is a development manager working for Cloe who is head of development reporting to Steve who is CTO reporting to Annabel who is CIO reporting to CEO Jack and the board. Somehow it didn't work. The going joke is: " If you want to get rid of job competitors internally, make sure they sit in the Taxonomy committee, that will tie them up and frustrate them down." Truth is: not everything fits into an hierarchy and agreeing on a term as the single permissible label for an item is a pipe dream (and what you would have to smoke in that pipe would be illegal in most jurisdictions). Especially with the rise of " PC" a committee might come to the compromise to call something " a human muscular traditional digging device" while mentally sane people will insist to " Call a spade a spade".
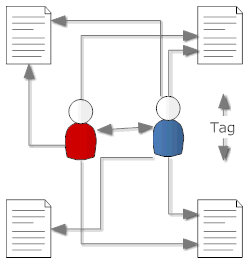 The rise of social computing with sites like Delicious or Digg added a new quality to classification attempts: tagging. With tagging suddenly naming something was given to all individual users rather than the "Committee of the final truth". Moreover items can be classified in any way thinkable and spade and classical digging device can coexist. Counting the occurrences a tag was associated with a term the "majority vote" or "common name" can be established without ditching the minority opinions. While it sounds messy it works well in practise and gets rapidly adopted in corporate social software.
The rise of social computing with sites like Delicious or Digg added a new quality to classification attempts: tagging. With tagging suddenly naming something was given to all individual users rather than the "Committee of the final truth". Moreover items can be classified in any way thinkable and spade and classical digging device can coexist. Counting the occurrences a tag was associated with a term the "majority vote" or "common name" can be established without ditching the minority opinions. While it sounds messy it works well in practise and gets rapidly adopted in corporate social software.
Besides classification by gravity tagging added additional meta information: when was it added, who added it, how popular is it. Especially the "who" seems to be an important factor. With the constant overload of information it becomes increasingly hard to check all the facts, so trustworthiness of the source, even if it is just the classification, becomes more and more important. So every tag associated with an item in fact is a linking vector with all these attributes, the tag value being just one of them. Ironically predating the tagging breakthrough we already had a standard to exactly do that: XLink.
Unfortunately no gain comes without collateral damage and the flat tagging got rid of marking "the official term" as well as the context covered by a taxonomy. When you see a tag " bank", what does it mean? A turning manoeuvrer of a plane, the edge of a river, the expression of trust (I bank on you) or a form of financial institution?
Delicious took an interesting approach by forming hierarchies out of the tags provided which leads to a huge number of permutations when the tag number increases - and not all make sense. Of course the question is: do the nonsensical matter since no one will ever follow them? Recognising that the core value of a tag lies in its links let to tools tools like The Brain, that allow you to link facts by simple dragging a line or pressing a button. The tag becomes a member of the information repository in its own right. Unfortunately the links don't carry the information "why" they exist ("is a", "contains", "runs", "owns" etc.). It will be interesting to see how the brain will adopt to collaborative linking needs.
The concept of trust was further developed by features like the Facebook like button or the voting capabilities in sites like StackOverflow or IdeaJam. It all reminds me of the ancient Germanic court room principle of proving plaintiff's trustworthiness rather than looking at facts. There are services that want to help to establish trustworthiness for URLs. All these attempts of classification have their merits, what is lacking is a unified field theory for classifications.
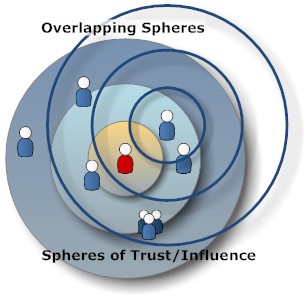
How to weight expert classifications (there is usually more than one, e.g. check for that really dangerous Dihydrogen monoxide), especially when they are unpopular, vs public opinion? How to quantify trust in your social graph (you would blindly follow Joe's music recommendations, but never ever let him near a kitchen to make food)?
So KM practitioners around the world have much to muse about. The key questions are still open: how to provide accurate, current, relevant and accessible know-how.
The trickiest problem in KM and to a large extend in eLearning is the classification of items. Taking a hint from classical science the first approach was to use a Taxonomy to build a tree of classification. Classification tree are well established and deeply entrenched in corporate hierarchies: a human is a hominid is a primate is a mammal is a vertebrate is a animal from the realm of living beings. Tom is an engineer who works for Frank who is a team leader who reports to Sue who is a development manager working for Cloe who is head of development reporting to Steve who is CTO reporting to Annabel who is CIO reporting to CEO Jack and the board. Somehow it didn't work. The going joke is: " If you want to get rid of job competitors internally, make sure they sit in the Taxonomy committee, that will tie them up and frustrate them down." Truth is: not everything fits into an hierarchy and agreeing on a term as the single permissible label for an item is a pipe dream (and what you would have to smoke in that pipe would be illegal in most jurisdictions). Especially with the rise of " PC" a committee might come to the compromise to call something " a human muscular traditional digging device" while mentally sane people will insist to " Call a spade a spade".
The rise of social computing with sites like Delicious or Digg added a new quality to classification attempts: tagging. With tagging suddenly naming something was given to all individual users rather than the "Committee of the final truth". Moreover items can be classified in any way thinkable and spade and classical digging device can coexist. Counting the occurrences a tag was associated with a term the "majority vote" or "common name" can be established without ditching the minority opinions. While it sounds messy it works well in practise and gets rapidly adopted in corporate social software.
Besides classification by gravity tagging added additional meta information: when was it added, who added it, how popular is it. Especially the "who" seems to be an important factor. With the constant overload of information it becomes increasingly hard to check all the facts, so trustworthiness of the source, even if it is just the classification, becomes more and more important. So every tag associated with an item in fact is a linking vector with all these attributes, the tag value being just one of them. Ironically predating the tagging breakthrough we already had a standard to exactly do that: XLink.
Unfortunately no gain comes without collateral damage and the flat tagging got rid of marking "the official term" as well as the context covered by a taxonomy. When you see a tag " bank", what does it mean? A turning manoeuvrer of a plane, the edge of a river, the expression of trust (I bank on you) or a form of financial institution?
Delicious took an interesting approach by forming hierarchies out of the tags provided which leads to a huge number of permutations when the tag number increases - and not all make sense. Of course the question is: do the nonsensical matter since no one will ever follow them? Recognising that the core value of a tag lies in its links let to tools tools like The Brain, that allow you to link facts by simple dragging a line or pressing a button. The tag becomes a member of the information repository in its own right. Unfortunately the links don't carry the information "why" they exist ("is a", "contains", "runs", "owns" etc.). It will be interesting to see how the brain will adopt to collaborative linking needs.
The concept of trust was further developed by features like the Facebook like button or the voting capabilities in sites like StackOverflow or IdeaJam. It all reminds me of the ancient Germanic court room principle of proving plaintiff's trustworthiness rather than looking at facts. There are services that want to help to establish trustworthiness for URLs. All these attempts of classification have their merits, what is lacking is a unified field theory for classifications.
How to weight expert classifications (there is usually more than one, e.g. check for that really dangerous Dihydrogen monoxide), especially when they are unpopular, vs public opinion? How to quantify trust in your social graph (you would blindly follow Joe's music recommendations, but never ever let him near a kitchen to make food)?
So KM practitioners around the world have much to muse about. The key questions are still open: how to provide accurate, current, relevant and accessible know-how.
Posted by Stephan H Wissel on 08 May 2011 | Comments (1) | categories: Software
