Cumulative data modeling (Part 2)

Continuing from Part 1: What if there is an alternative to a normalized RDBMS storage approach, that better fits the process flow?
The routing slip data model
Instead of looking at the physical entities (Suppliers, Ingredients, Cakes, Mixes, Slices etc.), look at the process steps and treat the process steps as our physical entities that store participating data.
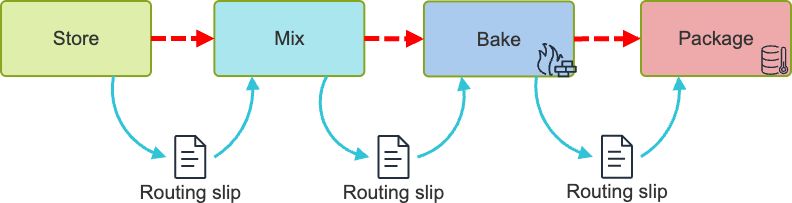
The main difference to normalization is to treat data as process local. 1kg flour in the mixing state is a different datapoint from 1kg four in storage silo 3. Routing slips provide the transition. Key difference: Routing slips are accumulative. So the routing slip in the package process contains all the routing slip data of previous process steps. From a database perspective that is a deliberate data duplication, raising blood pressure for data architects.
So why would you design in such a manner? The main advantage is self containment and transmissability. Any routing slip documents the pedigree/genesis of the physical product. A routing slip can be transmitted without the needs to run extraction code, so the process holds when execution gets split across independent entities. Since text storage is small (one cutecats.pptx is probably bigger than years of data), "not saving space" is an acceptable tradeoff. Another though: business documents tend to be self contained, or have you seen an invoice that lists a customerId, bot not the customer name or address?
Unsurprisingly such a data model is not relational, but document centric, so you are looking at MongoDB, CouchDB or any of the multi-model databases. Your data type would be JSON (while I could make, being old enough, a convincing case for XML, XSLT and XPath).
so how would the queries from part 1 look like? For simplicity I describe it in SQL blended with json path like syntax.
- a customer wants to know if the slice is made with cheese from "happy cows", which is a trade certification some of the suppliers have
SELECT slice_id, SUM(ingredients.cheese[happycow]) FROM slice_bucket['SomeSliceId']
- a batch from a supplier was sub standard and you need to recall all slices made with it.
SELECT slice_id FROM slice_bucket WHERE supplier.batch_id = `someBadBatchId`
You get the idea. As usual YMMV!
Posted by Stephan H Wissel on 04 May 2026 | Comments (0) | categories: CouchDB Development NoSQL SQL