On a quest for the best biking application

Preparing for my June adventure, I'm tracking my cycling progress. So far I tried Endomondo, RunKeeper and had a look at Strava. They all have their ups and downs:
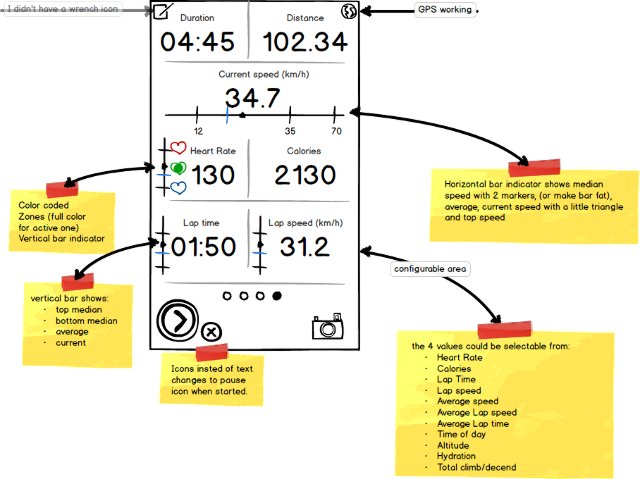
The big numbers are augmented with subtle hints on median performance using a bar display. Would be nice to see an app like that
- Endomondo doesn't provide a open data API and I never got the live broadcast working, but the UI is readable on a bike
- RunKeeper UI is too tiny for cycling mount, but live broadcast works nicely and the data API is open
- Strava doesn't seem to provide live updates, but rather tracking after the tour
- Battery live sucks for all of them
The big numbers are augmented with subtle hints on median performance using a bar display. Would be nice to see an app like that
Posted by Stephan H Wissel on 28 March 2014 | Comments (5) | categories: After hours Cycling

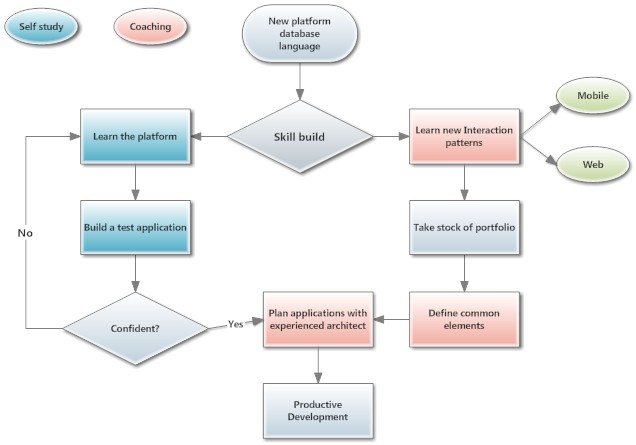

 ). My helpers look like this:
). My helpers look like this:

{kind=link}