Your API needs a plan (a.k.a. API Management)

You drank the API Economy cool aid and created some neat https addressable calls using Restify or JAX-RS. Digging deeper into the concept of micro services you realize, a https callable endpoint doesn't make it an API. There are a few more steps involved.
O'Reilly provides a nice summary in the book Building Microservices, so you might want to add that to your reading list. In a nutshell:
In IBM Bluemix there is the API Management service. This service isn't a new invention, but the existing IBM Cloud API management made available in a consumption based pricing model.
Your first 5000 calls are free, as is your first developer account. After that is is less than 6USD (pricing as of May 2015) for 100,000 calls. This provides a low investment way to evaluate the power of IBM API Management.
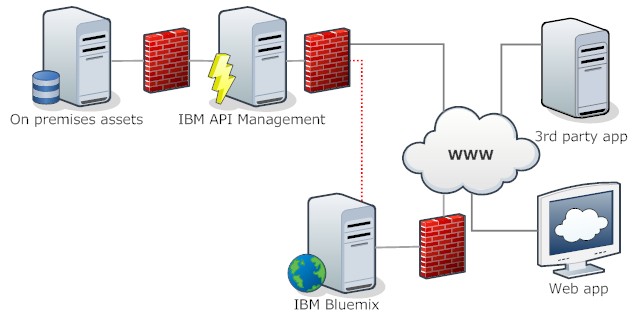
The diagram shows the general structure. Your APIs only need to talk to the IBM cloud, removing the headache of security, packet monitoring etc.
Once you build your API you then expose it back to Bluemix as a custom service. It will appear like any other service in your catalogue. The purpose of this is to make it simple using those APIs from Bluemix - you just read your
But you are not limited to use these APIs from Bluemix. You can call the IBM API management directly (your API partners/customers will like that) from whatever has access to the Intertubes.
There are excellent resources published to get you started. Now that you know why, check out the how:
As usual YMMV
O'Reilly provides a nice summary in the book Building Microservices, so you might want to add that to your reading list. In a nutshell:
- You need to document your APIs. The most popular tool here seems to be Swagger and WSDL 2.0 (I also like Apiary)
- You need to manage who is calling your API. The established mechanism is to use API keys. Those need to be issued, managed and monitored
- You need to manage when your API is called. Depending on the ability of your infrastructure (or your ability to pay for scale out) you need to limit the rate your API is called by second, hour or billing period
- You need to manage how your API is called. In which sequence, is the call clean, where does it come from
- You need to manage versions of your API, so innovations and improvements don't break existing code
- You need to manage grouping of your endpoints into "packages" like: free API, fremium API, partner API, pro API etc. Since the calls will overlap, building code for the bundles would lead to duplicates
In IBM Bluemix there is the API Management service. This service isn't a new invention, but the existing IBM Cloud API management made available in a consumption based pricing model.
Your first 5000 calls are free, as is your first developer account. After that is is less than 6USD (pricing as of May 2015) for 100,000 calls. This provides a low investment way to evaluate the power of IBM API Management.
The diagram shows the general structure. Your APIs only need to talk to the IBM cloud, removing the headache of security, packet monitoring etc.
Once you build your API you then expose it back to Bluemix as a custom service. It will appear like any other service in your catalogue. The purpose of this is to make it simple using those APIs from Bluemix - you just read your
VCAP_SERVICES.
But you are not limited to use these APIs from Bluemix. You can call the IBM API management directly (your API partners/customers will like that) from whatever has access to the Intertubes.
There are excellent resources published to get you started. Now that you know why, check out the how:
- Manage your APIs with the new IBM Bluemix Service
- Getting started with the Bluemix API Management Service
- Getting started with the API Management service (Official Bluemix documentation)
- IBM API Management Service documentation (IBM Knowledge base)
As usual YMMV
Posted by Stephan H Wissel on 20 May 2015 | Comments (0) | categories: Bluemix
