Workflow for beginners, Standards, Concepts and Confusion

The nature of collaboration is the flow of information. So naturally I get asked about Workflows and its incarnation in IT systems a lot. Many of the question point to a fundamental confusion what Workflow is, and what it isn't. This entry will attempt to clarify concepts and terminology
Wikipedia sums it up nicely: " A workflow consists of an orchestrated and repeatable pattern of business activity enabled by the systematic organization of resources into processes that transform materials, provide services, or process information. It can be depicted as a sequence of operations, declared as work of a person or group,[2] an organization of staff, or one or more simple or complex mechanisms".
Notably absent from the definition are: "IT system", "software", "flowchart" or "approval". These are all aspects of the implementation of a specific workflow system, not the whole of it. The Workflow Management Coalition (WfMC) has all the specifications, but they might appear as being written in a mix of Technobabble and Legalese, so I sum them up in my own words here:
Wikipedia sums it up nicely: " A workflow consists of an orchestrated and repeatable pattern of business activity enabled by the systematic organization of resources into processes that transform materials, provide services, or process information. It can be depicted as a sequence of operations, declared as work of a person or group,[2] an organization of staff, or one or more simple or complex mechanisms".
Notably absent from the definition are: "IT system", "software", "flowchart" or "approval". These are all aspects of the implementation of a specific workflow system, not the whole of it. The Workflow Management Coalition (WfMC) has all the specifications, but they might appear as being written in a mix of Technobabble and Legalese, so I sum them up in my own words here:
- A workflow has a business outcome as a goal. I personally find that a quite narrow definition, unless you agree: "Spring cleaning is serious business". So I would say: a collection of steps, that have been designed to be repeatable, to make it easier to achieve an outcome. So a workflow is an action pattern, the execution of a process. It helps to save time and resources, when it is well designed and can be a nightmare when mis-fitted
- A workflow has an (abstract) definition and zero or more actual instances where the workflow is executed. Like: "Spring cleaning requires: vacuuming, wiping, washing" (abstract). "Spring cleaning my apartment on March 21, 2014" (actual). Here lies the first challenge: can - and how much - a workflow instance deviate from the definition. How have cases to be handled when the definition changes in the middle of the flow execution? How to handle workflow instances that do require more or less steps? When is a step mandatory for regulatory compliance?
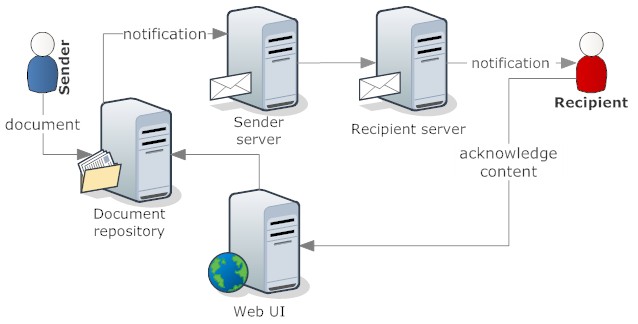
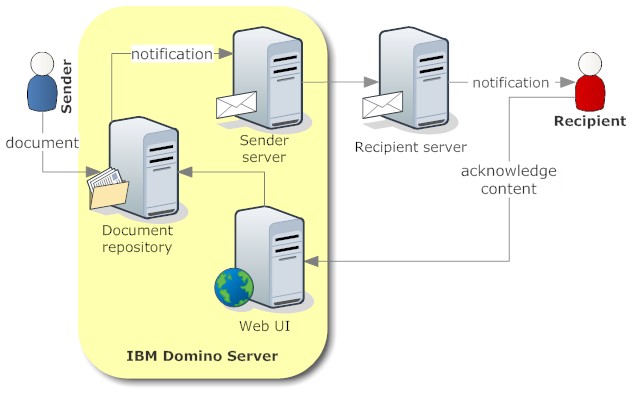
- A workflow has one or more actors. In a typical approval workflow the first actor is called requestor, followed by one or more approvers. But actors are not limited to humans and the act of approving or rejecting. A workflow actor can be a piece of software that adds information to a flow based on a set of criteria. A typical architecture for automated actors is SOA
- Workflow systems have different magnitudes. The flagship products orchestrate flows across multiple independent systems and eventually across corporate boundaries, while I suspect that the actual bulk of (approval) flows runs in self contained applications, that might use coded flow rules, internal or external flow engines
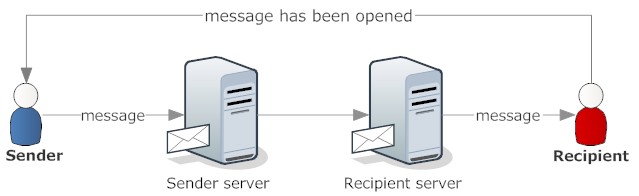
- On the other end of scale eMail can be found, where the flow and sequence are hidden in the heads of the participants or scribbled into freeform text
- Workflows can be described in Use Cases
, where the quality depends on the completeness of the description, especially the exception handling. A lot of Business Process Reengineering that is supposed to simplify workflows fails due to incomplete exception handling and people start to work "around the system" (eMail flood anyone?)
- A workflow definition has a business case and describes the various steps. The number of steps can be bound by rules (e.g. "the more expensive, the more approvers are needed" or "if the good transported is HazMat approval by the environmental agency is needed") that get interpreted (yes/no) in the workflow instance
- Determine the next actor(s) is a task that combines the workflow instance step with a Role resolver. That's the least understood and most critical part of a flow definition. Lets look at a purchase approval flow definition: "The requestor submits the request to approval by the team lead, to be approved by the department head for final confirmation by the controller". There are 4 roles to resolve. This happens in context of the request and the organisational hierarchy. The interesting question: if a resolver returns more than one person, what to do? Pick one randon, round robin or else how?
- A role resolver can run on submission of a flow or at each step. People change roles, delegate responsibilities or are absent, so results change. Even if a (human) workflow step already has a person assigned, a workflow resolver is needed. That person might have delegated a specific flow, for a period (leave) or permanently (work load distribution). So Jane Doe might have delegated all approvals below sum X to her assistant John Doe (not related), but that doesn't get reflected in the flow definition, only in the role resolution
- Most workflow systems gloss over the importance of a role resolver. Often the role resolver is represented by a rule engine, that gets confused with the flow engine. Both parts need to work in concert. We also find role resolution coded as tree crawler along an organisational tree. Role resolving warrants a complete post of its own (stay tuned)
- When Workflow is mentioned to NMBU (normal mortal business users), then two impressions pop up instantly: Approvals (perceived as the bulk of flows) and graphical editors. This is roughly as accurate as "It is only Chinese food when it is made with rice". Of course there are ample examples of graphical editors and visualizations. The challenge: the shiny diagrams distract from role definitions, invite overly complex designs and contribute less to a successful implementation than sound business cases and complete exception awareness
- A surprisingly novel term inside a flow is SLA. There's a natural resistance, that a superior (approver) might be bound by an action of a subordinate to act in a certain time frame. Quite often making the introduction of SLA part of a workflow initiative, provides an incentive to look very carefully to make processes complete and efficient
- Good process definitions are notoriously hard to write and document. A lot of implementations suffer from a lack of clear definitions. Even when the what is clear, the why gets lost. Social tools like a wiki can help a lot
- A good workflow system has a meta flow: a process to define a process. That's the part where you usually get blank stares

- Read a one one or
other good book to learn more
Posted by Stephan H Wissel on 24 July 2014 | Comments (2) | categories: Software Workflow






{kind=link}
{kind=link}
{kind=link}