Story Telling

Antoine de Saint Exupéry is attributed with the quote " If you want to build a ship, don't drum up the men to gather wood, divide the work and give orders. Instead, teach them to yearn for the vast and endless sea."
Story telling is a powerful medium to get "your message" across. It reaches far beyond the confines of ones early years and the collection lovingly preserved by The Brothers Grimm.
All of business runs on stories, when unleashed to customers often compressed into 30 seconds in high color ( super bowl anybody?).
We love to hear the latest stories about colleagues and celebrities (a.k.a. gossip) and spin our yarns how wonderful work will be when implementing [Insert the current fancy here].
In IT our stories are called use cases and transport the advantages of the new system or process to users who shouldn't care about the technical and implementation details. Since they tell a story about systems not yet in existence, could we call them "science finction"? Following our proposals will, in many cases, alter the way people work and perceive their work, so we should stick to good basic journalism to present it:
and transport the advantages of the new system or process to users who shouldn't care about the technical and implementation details. Since they tell a story about systems not yet in existence, could we call them "science finction"? Following our proposals will, in many cases, alter the way people work and perceive their work, so we should stick to good basic journalism to present it:
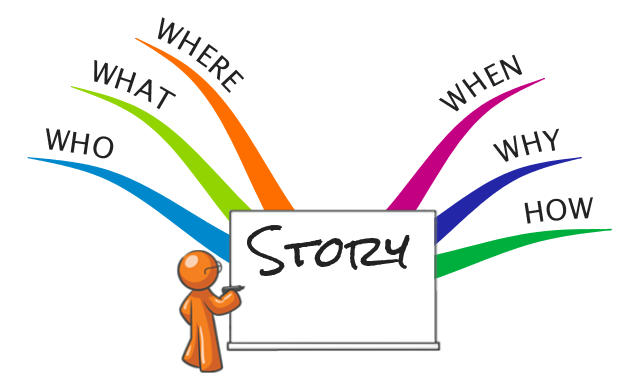
It doesn't harm when our stories are entertaining. Applying quis, quid, ubi, quando, cur and quomodo to other's stories helps to find the weaknesses in the plot. More often than not, the better story, not the better product wins. Despite the case for evidence based management stories beat facts by a long shot. So get your story right!
stories beat facts by a long shot. So get your story right!
Story telling is a powerful medium to get "your message" across. It reaches far beyond the confines of ones early years and the collection lovingly preserved by The Brothers Grimm.
All of business runs on stories, when unleashed to customers often compressed into 30 seconds in high color ( super bowl anybody?).
We love to hear the latest stories about colleagues and celebrities (a.k.a. gossip) and spin our yarns how wonderful work will be when implementing [Insert the current fancy here].
In IT our stories are called use cases
It doesn't harm when our stories are entertaining. Applying quis, quid, ubi, quando, cur and quomodo to other's stories helps to find the weaknesses in the plot. More often than not, the better story, not the better product wins. Despite the case for evidence based management
Posted by Stephan H Wissel on 31 March 2012 | Comments (1) | categories: After hours










 .
.